Huffman Encoder
Data Structures project to recreate the Huffman Encoding algorithm.
Role: Student | Date: April 25, 2018
Project Overview
- Project Type: Algorithm Recreation, Data Structures
- Tools Used: Java
-
Project Goals:
- Recreate Huffman Encoding algorithm.
- Encode text files into binary using the algorithm.
- Display the Huffman trees mapping to the correct char value.
- Revert the binary back to text.
The Problem / Challenge
Understanding how data structures operate in real-world applications is essential for developing efficient algorithms. This project, undertaken as a class assignment, focuses on implementing the Huffman Encoding algorithm in Java to reinforce concepts of data structures such as trees, priority queues, and frequency tables.
The goal is to construct a Huffman tree based on character frequencies, generate optimal binary codes for encoding text files, and develop a decoding mechanism to reconstruct the original text. Additionally, the project will include a visual representation of the Huffman tree and thorough testing to validate functionality.
Through this implementation, the assignment aims to enhance proficiency in data structures by applying them to a practical compression algorithm.
The Process
The process of creating the Huffman Encoding algorithm involves several key stages, each focusing on a different aspect of the project. From research and design to development and testing, these steps ensure that the algorithm is both effective and efficient for encoding and decoding data.
1. Research and Understanding the Algorithm
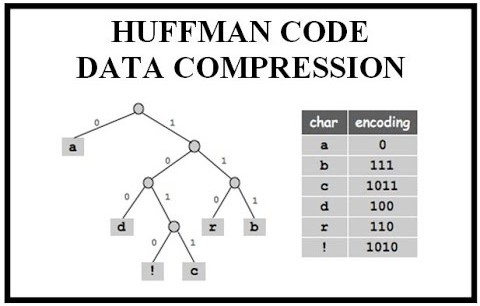
The first stage of the process is research. Before beginning the implementation, it is essential to understand how the Huffman Encoding algorithm works. This includes reviewing its principles, such as the frequency-based assignment of binary codes to characters. In this phase, we focus on understanding how to build the Huffman tree and generate optimal binary codes for data compression. This research helps set the foundation for the project and ensures the correct application of the algorithm.
2. Design and Development of Core Components
Once the core concepts are understood, the next phase is designing the solution. This involves planning how the different components of the project will work together. The design phase includes outlining the process, from reading the input text file to building the Huffman tree, generating binary codes, and implementing the encoding and decoding processes.
With the design in place, development begins. This phase involves the actual coding of the algorithm, starting with the construction of the frequency table. Using Java, the input text file is read and analyzed to count how often each character appears. From this frequency data, we can then proceed to build the Huffman tree.
The construction of the tree involves selecting the two characters with the lowest frequencies and combining them into an internal node. This step is repeated until only one node remains, creating the root of the tree. The tree is built in such a way that characters with higher frequencies are assigned shorter binary codes, optimizing the compression.
After the tree is constructed, the next step is to generate the binary codes for each character by traversing the tree. This involves assigning a "0" for left turns and a "1" for right turns in the tree, resulting in a unique binary code for each character.
With the binary codes established, the text encoding process begins. Each character in the input file is replaced with its corresponding binary code, creating the encoded output in binary form. Simultaneously, the decoding function is developed, allowing the binary data to be converted back into its original text form by traversing the Huffman tree based on the binary sequence.
3. Testing and Validation
Once the core components of the algorithm are developed, extensive testing is conducted. The tests focus on verifying that the encoding and decoding processes work correctly and that the binary output matches the expected result. Special attention is given to edge cases, such as files with repeating characters, files with unique characters, and empty files, to ensure the algorithm handles all scenarios efficiently.
Additionally, the binary file generated by the encoding process must be reversible during decoding. This is verified through test cases, where the encoded binary data is decoded back into the original text and compared for correctness.


Analysis
Huffman encoding is a simple and efficient algorithm used for data compression. It works by assigning shorter codes to more frequent symbols and longer codes to less frequent ones. This helps reduce the overall size of data, making it useful for compressing files like text or images. Its efficiency makes it a valuable tool in applications like file compression and data transmission, where saving space and reducing bandwidth usage are important.
Interested in working together on a similar project?