Expectation Maximization Clustering Algorithm
A team-based research project focused on recreating the Expectiation Maximization clustering algorithm
Role: Researcher | Date: December 2019
Project Overview
- Project Type: Application Developement, Research
- Tools Used: Python, Pandas, Numpy, C++
-
Project Goals:
- Recreate a custom version of the Expectation Maximization algorithm.
- Compare the Expectation Maximization algorithm to the Competative Agglomeration algorithm.
- Understand the use of clustering within Machine Learning and Artificial Intelligence.
- Use test dataset to analyze effectiveness of the algorithms.
The Problem / Challenge
This project involves developing a custom version of the Expectation Maximization (EM) algorithm in Python and comparing its performance to an existing implementation of the Competitive Agglomeration (CA) algorithm. The goal is to evaluate the effectiveness of both algorithms in Machine Learning and Artificial Intelligence applications, such as data clustering and pattern recognition. Using a variety of test datasets, the project will analyze key metrics like clustering accuracy, speed, and robustness to determine how well each algorithm performs. Insights from this research will guide improvements to the algorithms and provide recommendations for their use in practical machine learning tasks.
The Process
The main objective of this project was to compare the Competitive Agglomeration Algorithm (CGA) with the Expectation Maximization (EM) algorithm, focusing on time efficiency and accuracy. Since CGA was initially implemented in the C programming language, the first step was to convert it to Python. However, before making the comparison, it was necessary to modify the standard EM algorithm to incorporate techniques similar to those used in CGA, such as cluster pruning, which is not typically part of the EM algorithm.
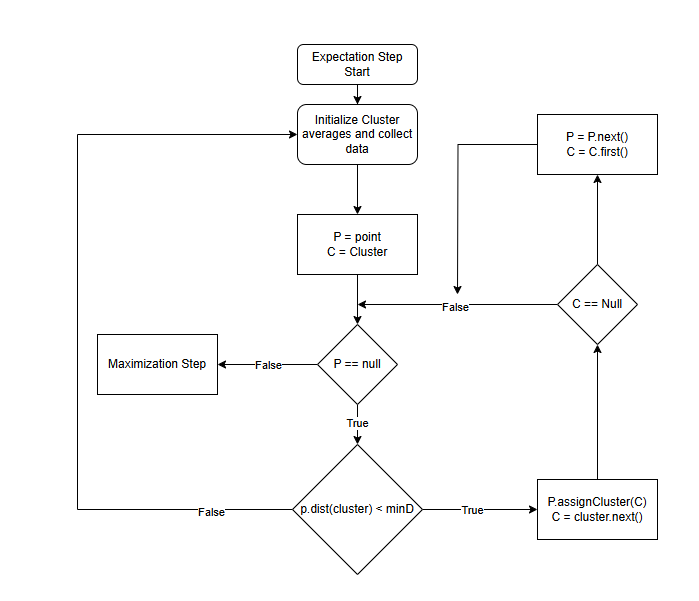
To begin, the Expectation Maximization (EM) algorithm was recreated in Python. The goal was to develop a version of EM that would facilitate a fair comparison to CGA, particularly in the way both algorithms assign data points to clusters. The EM algorithm was structured around its two main steps:
Expectation (E-Step)
In this step, each data point computes the Euclidean distance from itself to all available clusters and assigns itself to the closest one. The goal here is to calculate the likelihood that each point belongs to each cluster, based on these distances.
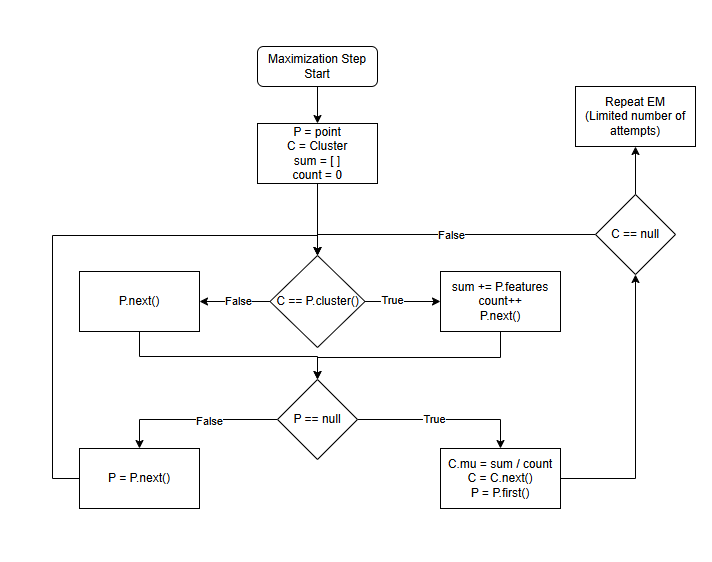
Maximization (M-Step)
After assigning points to clusters, the mean (or centroid) of each cluster is recalculated by averaging the points assigned to it.
To implement the EM algorithm in Python, Object-Oriented Programming (OOP) was employed. Key Python libraries such as pandas (for data manipulation and reading CSV files), numpy (for matrix operations), and time (for tracking execution times) were used. In the initial implementation, a cluster was represented by a list of points, and a Cluster class was used to store both the cluster's mean and the indices of the points assigned to it.
A challenge encountered during testing was that classifying points using indexes proved inefficient, especially when validating the output against a classification vector. To address this, the structure was changed, introducing a Point class to store the features of each data point and track which cluster it belongs to. This revised structure allowed for easier validation and comparison of the clusters.
Despite successfully implementing the standard EM algorithm, it needed modifications for the comparison with CGA. One of the significant changes was the addition of cluster pruning. Unlike the traditional EM algorithm, CGA automatically removes clusters that are deemed unnecessary. To simulate this behavior, a pruning mechanism was introduced in the EM algorithm. However, pruning clusters proved difficult as there is no universally accepted approach for doing so. After several attempts, the final pruning algorithm was designed to remove clusters with fewer than 8% of the total data points, which was shown to produce more accurate results.
Another important modification was the inclusion of Probability-Based Training Realignment (PBTR), recommended by the project advisor. PBTR is a technique where known data points are used to improve the alignment of clusters in the algorithm. It was implemented in the EM algorithm to test its impact on performance, particularly in improving accuracy.
By this point, the Expectation Maximization algorithm had been altered to match the features of CGA, including cluster pruning and PBTR. The next step was to run the algorithms with varying datasets to analyze and compare their performance.
Analysis
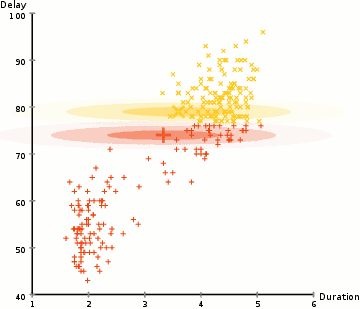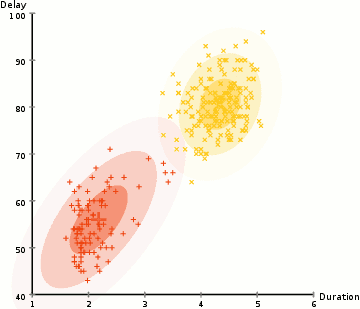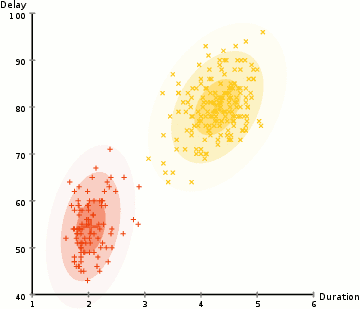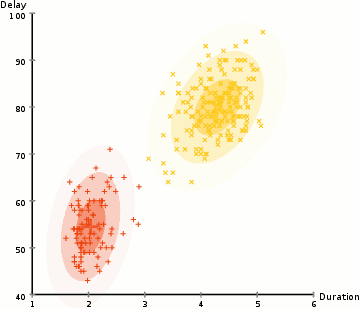
The performance of the Competitive Agglomeration Algorithm (CGA) and the modified Expectation Maximization (EM) algorithm was tested on various datasets, with the primary focus being on accuracy and time efficiency.
Using a large dataset of 25,000 data points and 784 features, both algorithms performed poorly, with accuracy below 5%, and training did not improve results. After switching to a smaller dataset with 3,000 data points and 2 features, the algorithms were more manageable and allowed for clearer comparisons.
The modified EM algorithm, with techniques like cluster pruning and PBTR, showed that pruning improved performance by speeding up the process, although PBTR introduced extra complexity without significant accuracy gains. In terms of accuracy, CGA outperformed the EM algorithm, with 79.53% accuracy compared to 70.17% for EM with pruning. However, CGA was much slower, taking 50 seconds to run, while the EM algorithm completed in about 3 seconds.
Interested in working together on a similar project?